Travel Time and Date in Rails Console
Usage
include ActiveSupport::Testing::TimeHelpers
travel_to 2.days.ago
Legacy Rails project and modern Assets Pipeline
One of the projects I’ve started a long-long time ago still powers the business. It was quite a journey starting from Rails 2, than Rails 3 and so on up until currently Rails 7 with plans to bump to Rails 8.
The project has live updates with Server Sent Events and a sidecar microservice to keep the connections and push updates. Quite similar to what DHH have done with ActiveCable, but based on different stack.
Hosting for Static Assets
I lived on GitHub Pages for static hosting for a long time. For example, this blog been hosted as https://mprokopov.github.io for years, just with the custom domain https://prokopov.me
But last week I finally moved everything to CloudFlare Pages and quite happy about it!
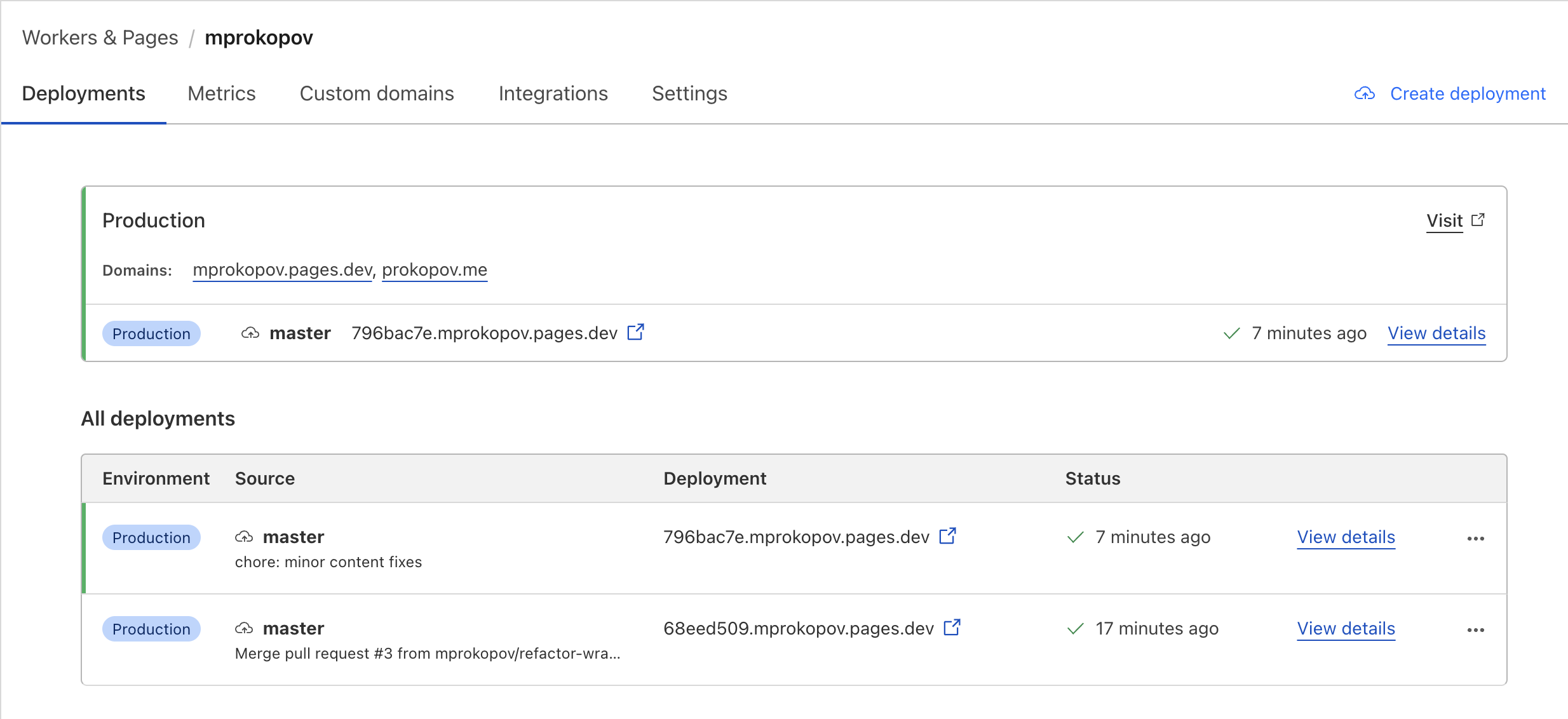
The major driver for the change was a hassle of management github-pages. It’s either your have to keep everything in a separate branch, with the name like github-pages, or have to use completly different repository.
I chose the latter, and for a long time kept using two repositories, one with Hugo sources, second with rendered HTML. It was a bit painful to manage two git repositories in the same working tree, hugo build renders the website to the public folder. In addition, the repository with HTML should be public.
Ghostty Remap Cmd to Control under macOS
Ghostty is ridiculously fast. But there’s one thing that bugged me: my thumbs.
Terminal shortcuts expect Control. Ctrl + a for line start, Ctrl + e for line end, Ctrl + k to kill the rest of the line. These are Emacs-style readline bindings, baked into every shell since the 80s.
Mac keyboards bury Control in the corner. Command sits right under your thumb where it belongs. I kept reaching for Command and getting nothing.
Trigger Jenkins job on EC2 termination event
Example of the Python code to catch EC2 termination signal and ping Jenkins to run termination job. Useful to execute graceful shutdown if you’re using EC2 spot instaces.
You will need Jenkins Generic Webhook plugin.
import json
import boto3
import urllib3
import os
JENKINS_JOB_TOKEN = os.environ.get('JENKINS_TOKEN')
JENKINS_URL = os.environ.get('JENKINS_URL')
def invoke_jenkins(target):
http = urllib3.PoolManager()
return http.request('POST', f"{JENKINS_URL}/generic-webhook-trigger/invoke?instance={target}", headers={'Authorization': f"Bearer {JENKINS_JOB_TOKEN}"})
def find_target(instance_id):
ec2 = boto3.client("ec2")
tags = ec2.describe_tags(Filters=[{'Name': 'resource-id', 'Values': [instance_id]}])
for tag in tags['Tags']:
if tag['Key'] == "Name":
return tag['Value']
def lambda_handler(event, context):
instance_id = event["detail"]["instance-id"]
target = find_target(instance_id)
if not target:
return {
'statusCode': 422,
'body': f"target for {instance_id} not found"
}
print(f"Jenkins termination job called for instance: {instance_id} target {target}")
resp = invoke_jenkins(target)
print(f"Jenkins response status {resp.status}")
print(f"Jenkins decoded response")
print(resp.data.decode('utf-8'))
return {
'statusCode': resp.status,
'body': json.dumps(resp.data.decode('utf-8'))
}
HashiCorp Nomad reschedule a Job
HashiCorp Nomad Job
It’s often the job increases retry counter, but there is no time to waste after the root cause of failing job being removed.
Here is the way to enforce re-run of the job. Unfortunately, I couldn’t find any means to achieve the same from the UI
nomad job eval -force-reschedule rundeck
On interpreter and dependenencies management problem
The problem
The problem of interpreter and dependency management is quite common, but also challenging.
- Appliations sometimes are written using interpreted languages. Examples:
brewin Ruby,ansiblein Python. - Software development. For instance, mainstream AI development requires Python.
In order to run they always need two things:
- Interpreter
- Dependencies
This boils down to the following problems. How to download and keep interpreters of different versions? How to download, keep and manage dependencies? How to include or not to include the interpreter and dependencies into a distribution?
GitHub Markdown preview with Grip and UV
It’s common task to prepare README.me, but how to check the preview?
If you use uv, the fastest way is to use grip like this
Use this oneliner in the folder with markdown and open browser with http://localhost:6419 address
uv run --with grip -m grip
which is the same as
uv tool run grip
or even shorter
uvx grip
How to Use Model Control Protocol with Claude AI to work with your private data
Learn how to access and work with your private data using Large Language Models with Model Control Protocol.
Cloud Cost Management aka FinOps
Cloud Cost Management, or FinOps is tricky. Imagine Team A started consuming much more resources and the management just starts seeing hair-pulling consequences at the end of the month in AWS bill.

How to react fast and prevent unnecessary cost? Or become very restrictive by blocking spinning up a new resources w/o explicit management approval, this can slow down and progress and also can be catastrophic for the company.