Less Distraction, More Focus
In case you think the environment full of distraction and context switching introduces such negative effects as reduction of ability to stay focused on a single task for long enough, you’re not alone. No time for long reads, shorter interactions, anxiety and fear of missing out. Yeah, it’s real.
I’d like to share results of my current ongoing experiment highly inspired by this video, which I definitely recommend for watching
RunDeck Set Admin Password
RunDeck is an excellent tool from PagerDuty to automate certain tasks.
Suprisingly, resetting default admin user password in a docker container isn’t easy.
Default username is admin and the password is admin. Apparently, this is not the securest password, and needs to be changed.
To update it in the container, you have create a file
/home/rundeck/server/config/realm.properties with the contents
admin:YourNewPassword,user,admin
though, if you want to be more secure (I assume that you’d want).
Upgrading Rails to 8.1 and fixing incompatible gems
You probably faced similar error.
Could not find compatible versions
Because every version of paranoia depends on activerecord >= 6, < 8.1
and rails >= 8.1.0 depends on activerecord = 8.1.0,
every version of paranoia is incompatible with rails >= 8.1.0.
So, because Gemfile depends on rails ~> 8.1
and Gemfile depends on paranoia = 3.0.1,
version solving has failed.
This means your gem paranoia wants activerecord with version less than 8.1, but you tested and know it should work.
Rails Suppressor Pattern
While grokking through Rails source code, one pattern caught my eye, namely Suppressor.
Here is the full listing, and as you could spot, it’s quite concise.
But, I spent some time trying to figure out how it works in the context of ActiveRecord. How does it suppress callbacks and notifications?
Honestly, it took me a while to figure out. Give yourselve several minutes to read through the code. It’s really there!
Chrome Command Palette in Dev Tools
I was today years old when I learned about Cmd + Shift + p command palette in Google Chrome.
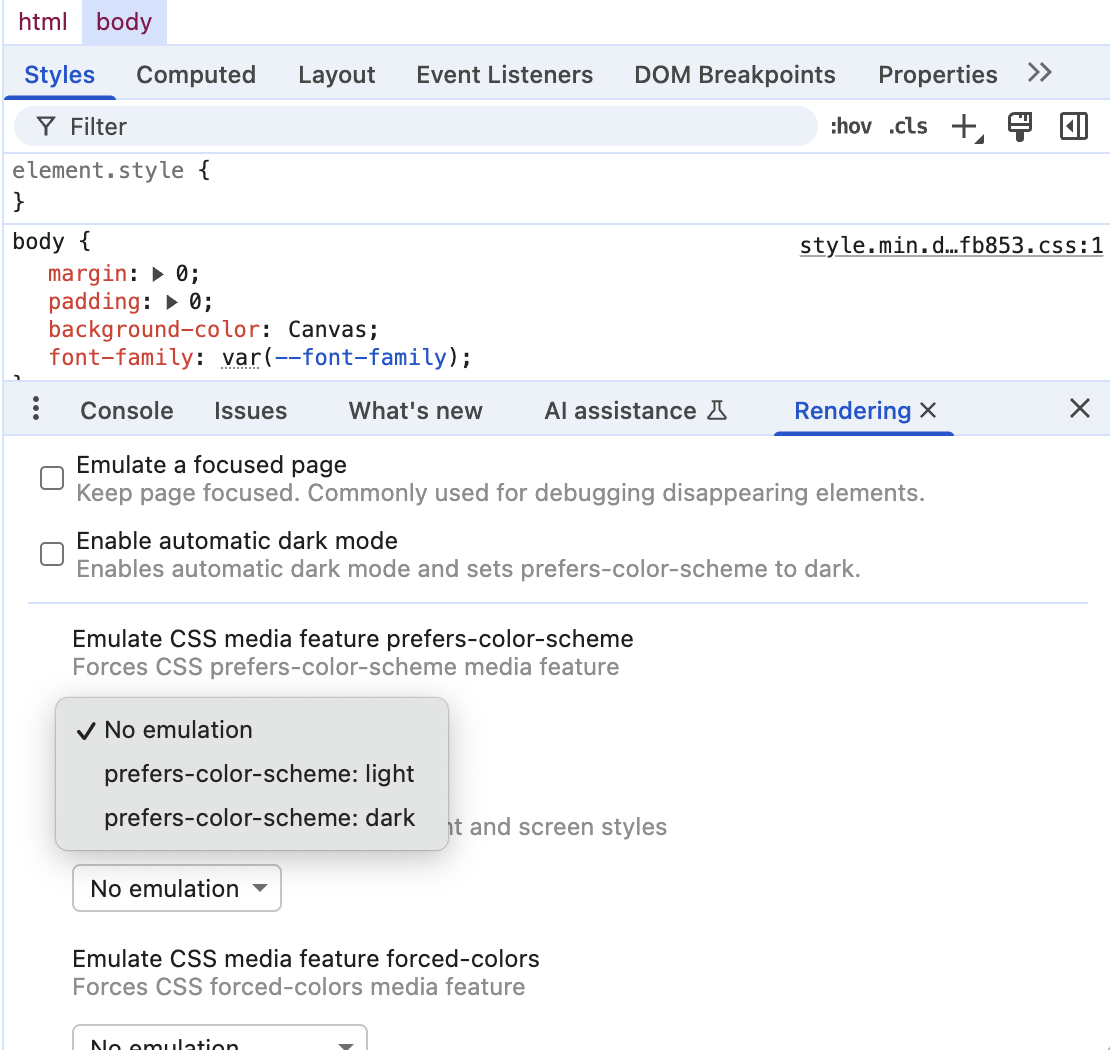
Why you might need it?
To enable dark mode emulation!
Adding PDF previews to ActionText with ActiveStorage
Rails is a great framework, once you stop thinking in Java patterns and embraice DHH way of writing web apps.
Interestingly, Basecamp uses exactly the same ActiveStorage implementation, but shows full-size and download links alone with the PDF attachment. But if you only follow the guide, it’s hard to implement by your own without some gotchas.
These gotchas I want to capture here in this how-to article. It assumes reader followed official guide and stuck with PDF thumbnails preview implementation.
Stop writing data migrations
As many of us, I was writing data migrations as a part of database schema migrations.
Why that’s a bad practice, and what’s the better way to do this.
- Your data migration typically comes along with changes to schema. Do you have the data migration together with schema migration?
- If your data processing fails in the middle of migration, what’s the way to resume it?
- Do you ever need it again? I.e. does it make sense to keep this migration in migrations history?
If you tick at least two checks, congrats, you don’t have to keep data migrations with schema migrations. Just write a script, execute it and throw away!
Vanilla Rails is Enough
Argh, some things I should have learned earlier!
One of these is this brilliant blog post Vanilla Rails is plenty couldn’t have bigger influence on me. Believe me or not, I wrote Rails wrong since 2007 🤦♂️.
Here is the list of gems i’m ditching out of my Rails projects.
- knockout-rails
- paloma
- simple-form
- rails-timeago
- carrierwave
- resque
- resque-web
- resque-scheduler
-- we are here --
- devise
- haml
- factory-bot
- rspec
- bower-rails
- sprockets
- google-visualr
- recurring-select
- select2-rails
- pundit
adding a few
Get GitHub Teams CLI Snippet
GitHub CLI is a nice way to query GitHub API locally
gh api orgs/<org>/teams | jq '.[] | {name,slug}'
Travel Time and Date in Rails Console
Usage
include ActiveSupport::Testing::TimeHelpers
travel_to 2.days.ago